
Deliver Scientific Data 10x Faster, Without Replatforming or Lock-In
End cold-data delays, manual syncs, and cross-site duplication so teams can launch jobs faster -
without rework or complexity.
See how it fits in your environment, in 15 Minutes




If you run a scientific infrastructure, you’ve likely hit all three of these blockers:

Staging & Sync Delays
Cryo-EM, genomics, and imaging pipelines stall when storage lags. Especially across sites.
Siloed Storage
Scientists, IT, and partners are stuck on disconnected systems, with no unified access or visibility

Vendor Lock-In
Legacy vendors force rigid licensing and hardware lock-in, slowing cloud adoption.
Qumulo solves all three – without forcing a replatform.
Accelerate scientific workflows without disrupting your stack
Eliminate silos with real-time data access across every site
Deploy anywhere without vendor lock-in

Deliver faster science, cut delays to seconds, and unify data across any site, without disruption
Modern pipelines can't outrun outdated storage
Your pipelines, teams, and compute are still waiting for the data to catch up
Storage bottlenecks stall analysis
Research data piles up in queues. Having to be staged, moved or cleared manually, before compute can even begin

Too many systems, too many failure points
Cryo-EM, Omics, and AI pipelines depend on scripts, gateway tools, and cloud staging layers, adding risk and delay

Infrastructure duplicated to span on-prem and cloud
To meet cloud and core requirements, teams maintain multiple systems or replatform - wasting time and budget.

Collaboration slowed by file system limitations
Cloud performance, data residency, or version control challenges block teams from accessing the data they need.
Data delays between lab instruments and compute
Scientific data waits in queues. Staged or manually moved before compute can begin
Pipelines stitched together with too many systems
Cryo-EM, Omics, and AI workflows depend on scripts, gateway tools, and cloud staging layers - all adding risk and complexity
Infrastructure duplicated to span on-prem and cloud
To meet cloud and core requirements, teams maintain multiple systems or replatform - wasting time and budget.
Collaboration slowed by file system limitations
Cloud performance, data residency, or version control challenges block teams from accessing the data they need.
These aren't edge cases. They're architecture-level blockers baked into the systems
you're expected to scale
Modern pipelines can't outrun outdated storage
Your pipelines, teams, and compute are still waiting for the data to catch up
Storage bottlenecks stall analysis
Research data piles up in queues. Having to be staged, moved or cleared manually, before compute can even begin
Too many systems, too many failure points
Cryo-EM, Omics, and AI pipelines depend on scripts, gateway tools, and cloud staging layers, adding risk and delay

Infrastructure duplicated to span on-prem and cloud.
To meet cloud and core requirements, teams maintain multimple systems or replatform - wasting time and budget.
Collaboration slowed by file system limitations
Cloud performance, data residency, or version control challenges block teams from accessing the data they need.
These aren't edge cases. They're architecture-level blockers baked into the systems you're expected to scale
Want to see what this looks like in your environment?
You can walk through how other teams are addressing these challenges or check your own scientific data readiness in 60 seconds
You can walk through how other teams are addressing these challenges or
check your own scientific data readiness in 60 seconds
Here's what makes Qumulo different, and why it works for scientific infrastructure
Legacy and cloud first file systems weren't built to keep up with scientific scale. Qumulo eliminates the delays they introduce, without rework, sync tools, or silos.

Cloud Data Fabric
Access files instantly, from anywhere.
Without moving, syncing or staging them.

Global Access
No replication. No lag. No silos.
Run Anywhere
x86, ARM, virtual, cloud-native.
Neural Cache
4x faster jobs. 99% fewer object calls.

Cloud Native Qumulo (CNQ)
Deploy in AWS, Azure, GCP+. No app rewrites

No Gateways. No sync agents. No rebuilds
Eliminates overlays, manual sync,
and versioning agents
Engineered to eliminate storage friction – from lab to cloud to compute
Here's what makes Qumulo different,
and why it works for scientific infrastructure
Legacy and cloud first file systems weren't built to keep up with scientific scale. Qumulo eliminates the delays they introduce, without rework, sync tools, or silos.
Cloud Data Fabric
Access files instantly, from anywhere.
Without moving, syncing or staging them.
Global Access
No replication. No lag. No silos.
Run Anywhere
x86, ARM, virtual, cloud-native.
Neural Cache
4x faster jobs. 99% fewer object calls.
Cloud Native Qumulo (CNQ)
Deploy in AWS, Azure, GCP+. No app rewrites
No Gateways. No sync agents. No rebuilds
Eliminates overlays, manual sync, and versioning agents
Engineered to eliminate storage friction – from lab to cloud to compute
From hours or days of staging, syncing,
and waiting... to sub-second delivery
See the Difference Qumulo Makes - Before vs. After
Scientific teams using Qumulo move from data capture to compute in minutes - not days
Want to see how?
Grab your 15 Min Walkthrough
Qumulo is not a storage upgrade. It's a data delivery engine
Built to eliminate delays caused by staging, replication, and cloud I/O bottlenecks.
So your Scientific workflows run faster on infrastructure designed for research
Qumulo is a software-defined file data platform that delivers real-time access to unstructured data across lab, on-prem, cloud, and edge.
No Replatforming.
No Rewritten apps.
No Duplicated storage.
Built for infrastructure and Ops leaders, Qumulo includes:
Cloud Data Fabric
Unify workflows across edge, on-prem,
and cloud

CNQ
Deploy Cloud Native Qumulo in AWS, Azure, GCP. Elastic, cost efficient, fully cloud native
Run Anywhere
Any platform, any workload, x86, ARM, virtualized or bare metal
Neural Cache
Launch jobs faster
Predicts access + minimizes object read latency
No Replatforming.
No Rewritten apps.
No Duplicated storage.
Built for infrastructure and Ops leaders, Qumulo includes:
Cloud Data Fabric
Unify workflows across edge, on-prem, and cloud
CNQ
Deploy Cloud Native Qumulo in AWS, Azure, GCP. Elastic, cost-efficient, fully cloud-native
Run Anywhere
Any platform, any workload, x86, ARM, virtualized or bare metal
Neural Cache
Launch jobs faster
Predicts access + minimizes object read latency
Trusted by Organizations Where Scientific Discovery Depends on Infrastructure
Enterprise R&D teams, national labs, and academic research centers use Qumulo to solve data challenges in Cryo-EM, Genomics, and AI-driven science. Moving petabytes of unstructured data without delay, disruption, or replatforming.
From delays to instant access - How Qumulo unblocks compute
BEFORE
Hours lost waiting for data to land
Manual staging delays pipelines and compute
Pipelines break across silos
Gateway tools and sync scripts create failure points
Scientific teams wait on IT
GPUs idle while waiting for file access
AFTER
Direct file delivery from lab to compute
- Cloud Data Fabric
One global file system with no sync or duplication
- Run Anywhere
Jobs Start 2-4x faster, no pipeline rewrites
- Neural Cache + CNQ
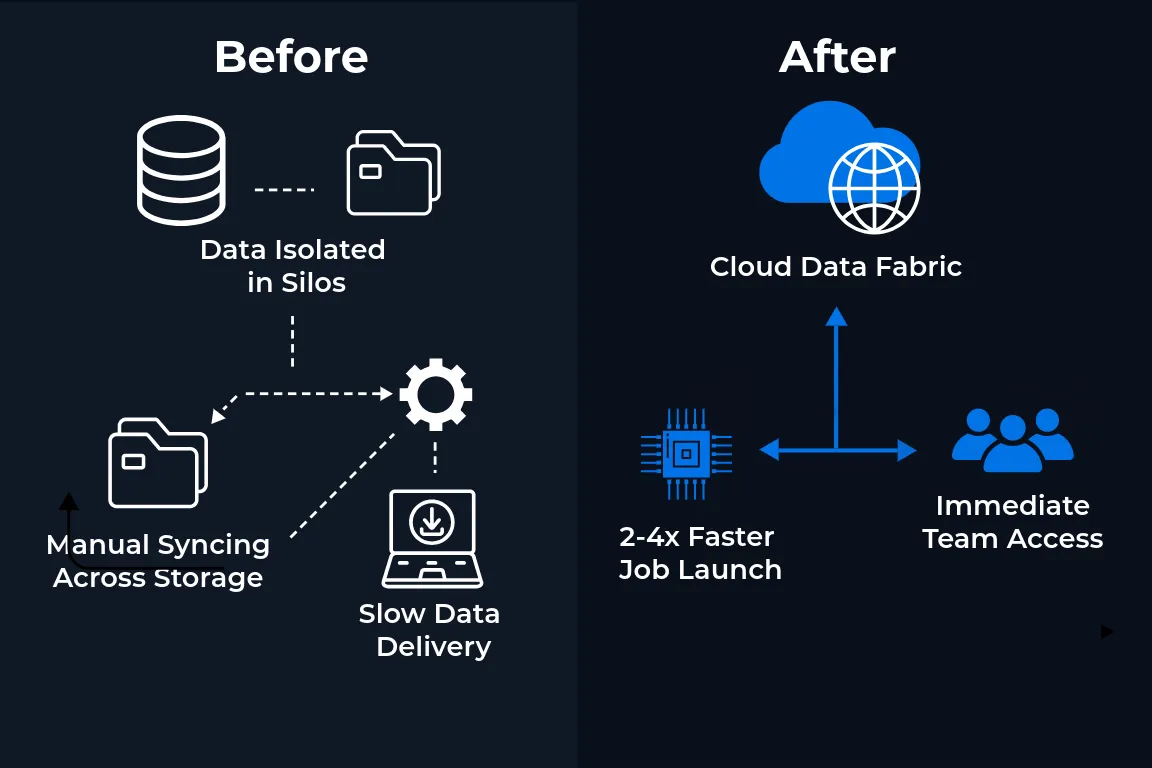
Qumulo eliminates all 3 blockers: No rewrites, no replication, no delay
From delays to instant access - How Qumulo unblocks compute
BEFORE
Hours lost waiting for data to land
Manual staging delays pipelines and compute
Pipelines break across silos
Gateway tools and sync scripts create failure points
Scientific teams wait on IT
GPUs idle while waiting for file access
AFTER
Direct file delivery from lab to compute
Cloud Data Fabric
One global file system with no sync or duplication
Run Anywhere
Jobs Start 2-4x faster, no pipeline rewrites
Neural Cache + CNQ

Qumulo eliminates all 3 blockers: No rewrites, no replication, no delay
Remove Data Delivery Delays
See how to eliminate staging, replication, and slow job starts for infra teams in pharma
5 Use Cases
5 Use Cases
What Happens When You Remove the Storage Bottlenecks
Infra/Ops teams deliver scientific data to compute faster, scale hybrid pipelines without duplication, and eliminate synch jobs, agents, and delay.
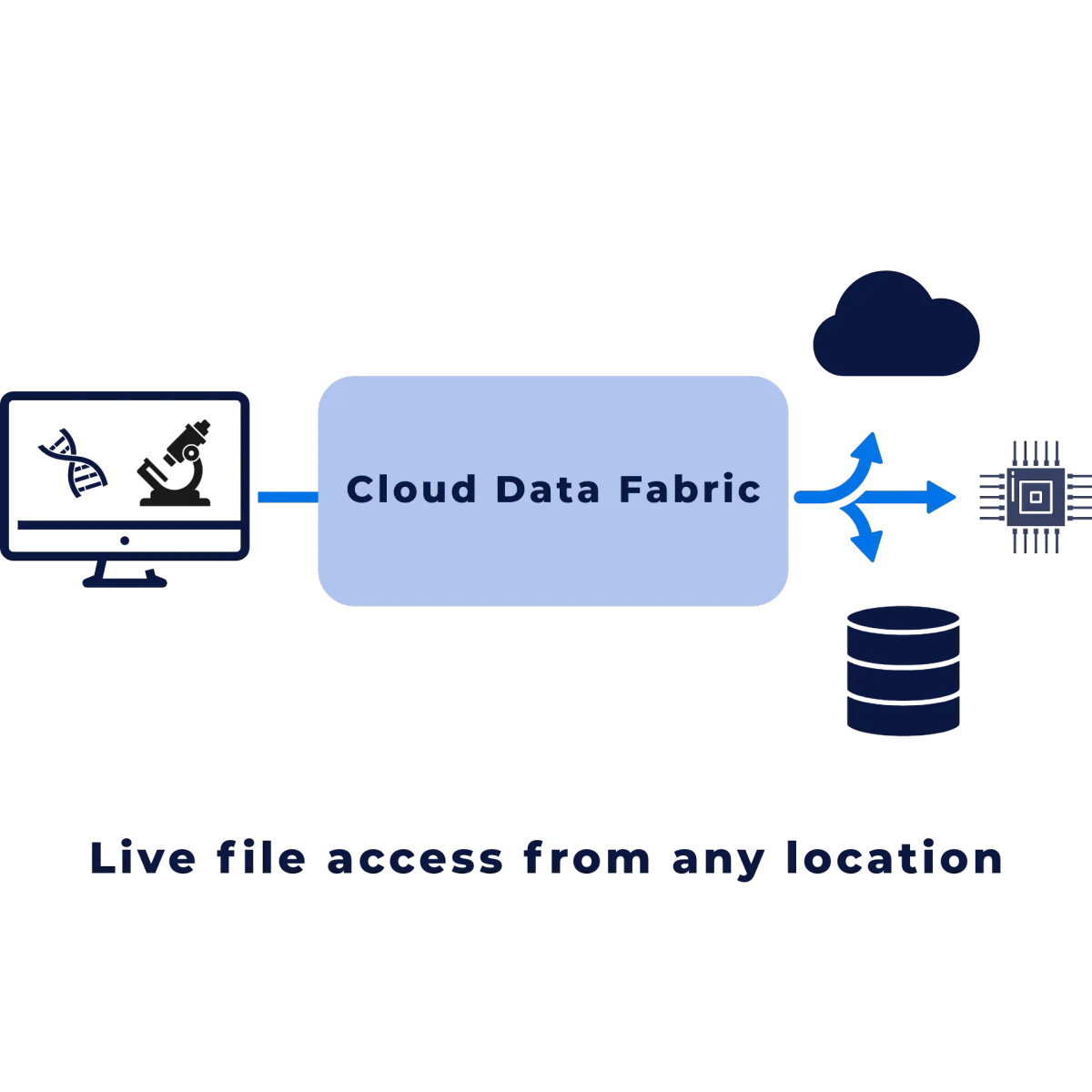
Live, version-correct access across global teams
Powered by: Cloud Data Fabric + Run Anywhere Architecture
We eliminated replication scripts
Every Region has real-time read/write access
No manual sync. No delay
Hybrid cloud pipelines deployed with zero disruption
Powered by: Cloud Native Qumulo + Flexible Deployment
Moved to Cryo-EM to cloud in 30 days
No pipeline rewrites
No architecture or user impact
2-4x faster jobs starts from lab to GPU
Powered by: Neural Cache + Cloud Data Fabric
Sub-second file access from the lab
No object queueing or staging
AI pipelines launched immediately
What Happens When You Remove the Storage Bottlenecks
Infra/Ops teams deliver scientific data to compute faster, scale
hybrid pipelines without duplication, and eliminate synch jobs,
agents, and delay.
Live, version-correct access across global teams
Powered by: Cloud Data Fabric + Run Anywhere Architecture
We eliminated replication scripts
Every Region has real-time read/write access
No manual synch. No delay
Hybrid cloud pipelines deployed with zero disruption
Powered by: Cloud Native Qumulo + Flexible Deployment
Moved to Cryo-EM to cloud in 30 days
No pipeline rewrites
No architecture or user impact
2-4x faster jobs starts from lab to GPU
Powered by: Neural Cache + Cloud Data Fabric
Sub-second file access from the lab
No object queueing or staging
AI pipelines launched immediately
See Qumulo in Action - Get a 15 Min Walkthrough
Show us one workflow. We'll show you proof in 15 minutes.
You'll meet directly with Gregg & Marcos, the dedicated Qumulo LIfe Science team
Eliminate staging, syncing, and manual data movement
Deliver lab data straight to compute and collaborators
Cut data delivery times from days or hours to minutes
Scale hybrid performance - no rewrites, no replatforming

Built for the Way Science Moves
You're not managing file systems, you're managing petabytes of scientific data across teams, instruments, software, and timelines.
Qumulo was built for that.
Copyrights 2025 | Qumulo™ | Terms & Conditions | Privacy Policy